Linear regression
This page contains advanced examples for the tno.quantum.ml.regression.linear_regression package.
Examples of basic usage can be found in the module’s documentation.
Requirements
Install the following dependencies to run the examples below:
pip install tno.quantum.ml.regression.linear_regression
pip install seaborn
Examples
Example 1: Assume a linear system of the form \(Ax=b\) where:
\(A\) is the training data.
\(x\) is a vector of unknown coefficients.
\(b\) is a vector of target values.
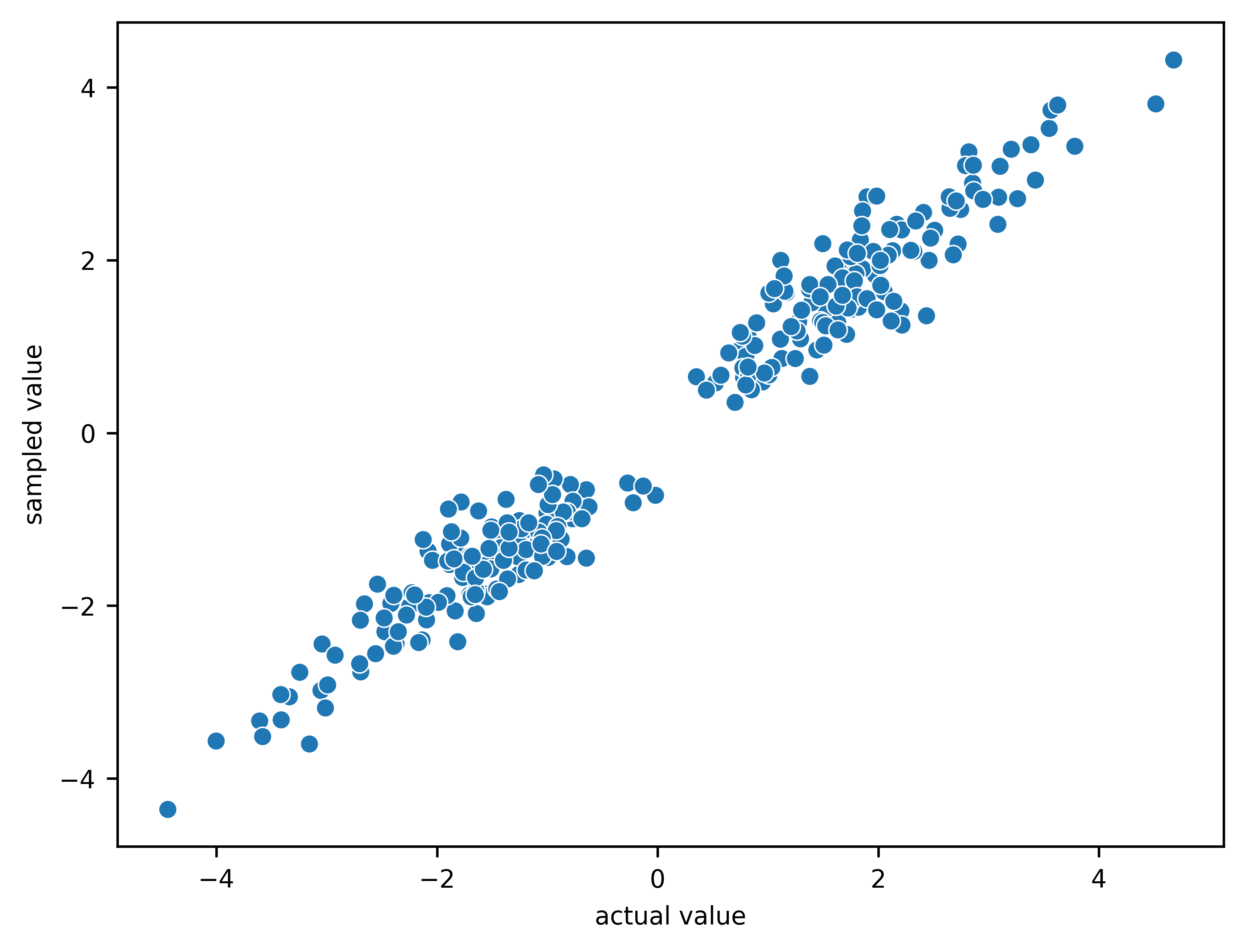
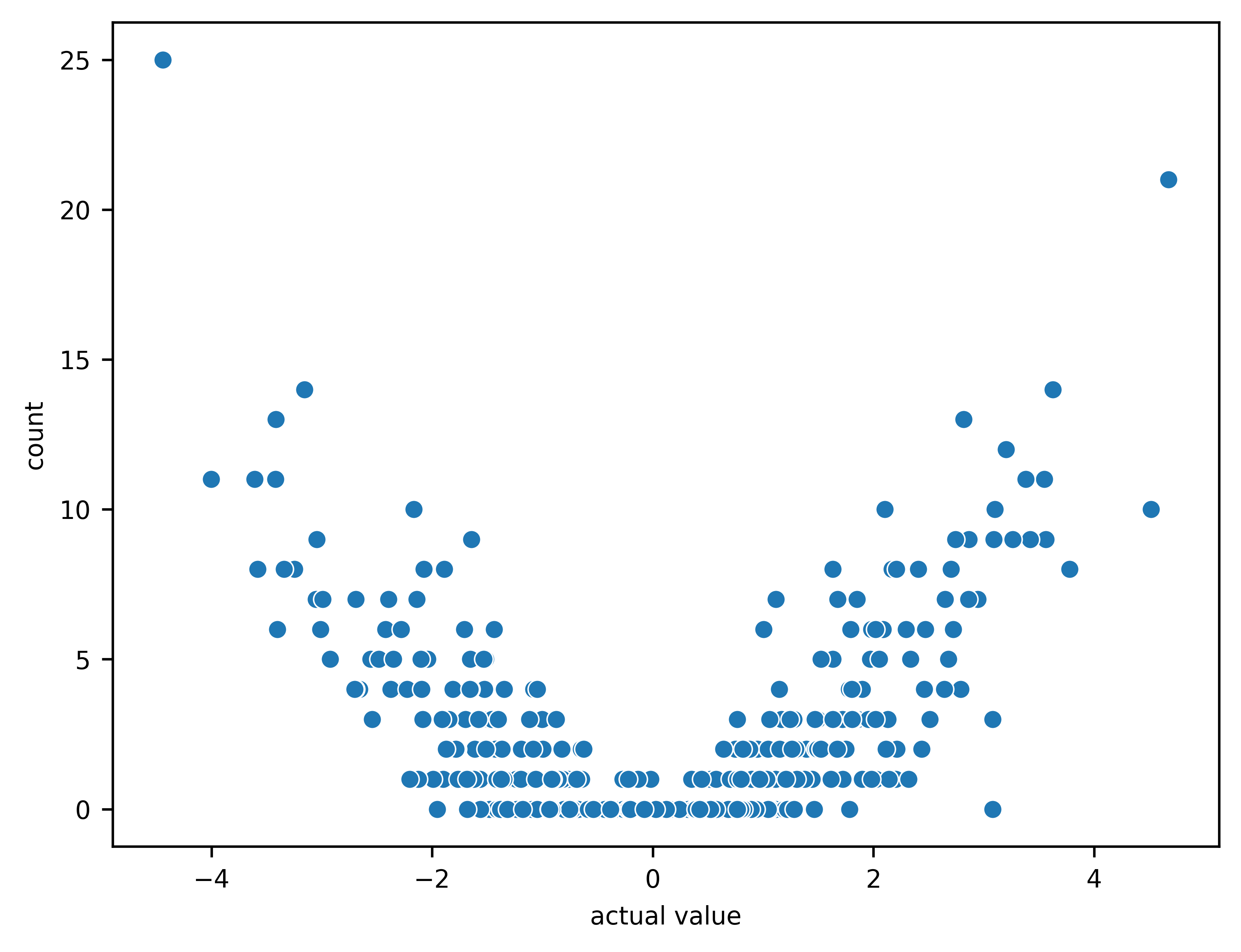
The following fits the model based on \(A\) and \(b\), and shows the following relationships:
The sampled values (predictions) for \(b\) versus their actual values.
The sampled values (predictions) for \(b\) versus their sampling count (i.e., the number of times the corresponding index has been sampled).
Note that larger values are sampled more often as expected.
1import logging
2
3import matplotlib as mpl
4import numpy as np
5import pandas as pd
6import seaborn as sns
7
8from tno.quantum.ml.regression.linear_regression import QILinearEstimator
9
10mpl.use("Agg")
11import matplotlib.pyplot as plt
12
13plt.rcParams["font.size"] = "8"
14
15logging.basicConfig(
16 format="%(levelname)s:%(message)s", level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S"
17)
18
19
20def _save_fig(name: str) -> None:
21 plt.savefig(name, dpi=600, bbox_inches="tight")
22 plt.close("all")
23
24
25def run_example() -> None:
26 """Example of quantum-inspired linear prediction."""
27 random_state = 111
28
29 # Load data
30 rank = 3
31 m = 500
32 n = 250
33 rng = np.random.RandomState(random_state)
34 A = rng.normal(0, 1, (m, n))
35 U, S, V = np.linalg.svd(A, full_matrices=False)
36 S[rank:] = 0
37 A = U @ np.diag(S) @ V
38 x = rng.normal(0, 1, A.shape[1])
39 b = A @ x
40
41 # Solve using quantum-inspired algorithm
42 rank = 3
43 r = 100
44 c = 100
45 n_samples = 100
46 n_entries_b = 1000
47 sketcher_name = "fkv"
48 qi = QILinearEstimator(
49 r, c, rank, n_samples, random_state, sketcher_name=sketcher_name
50 )
51 qi = qi.fit(A, b)
52 sampled_indices, sampled_b = qi.sample_prediction_b(A, n_entries_b)
53
54 # Process results
55 df = pd.DataFrame({"b_idx_samples": sampled_indices, "b_samples": sampled_b}) # noqa: PD901
56 df_counts = df.groupby("b_idx_samples")["b_idx_samples"].count()
57 unique_sampled_indices = np.asarray(df_counts.keys())
58 counts = np.asarray(df_counts.values)
59 df_mean = df.groupby("b_idx_samples")["b_samples"].mean()
60 unique_sampled_indices2 = np.asarray(df_mean.keys())
61 unique_sampled_b = np.asarray(df_mean.values)
62 assert np.all(unique_sampled_indices == unique_sampled_indices2)
63
64 # Plot results
65 b_counts = np.zeros(b.size)
66 b_counts[unique_sampled_indices] = counts
67 b_vs_sampled_counts_df = pd.DataFrame({"actual value": b, "count": b_counts})
68 sns.scatterplot(data=b_vs_sampled_counts_df, x="actual value", y="count")
69 _save_fig("example1-actual_value_vs_count")
70
71 b_vs_avg_sampled_b_df = pd.DataFrame(
72 {"actual value": b[unique_sampled_indices], "sampled value": unique_sampled_b}
73 )
74 sns.scatterplot(data=b_vs_avg_sampled_b_df, x="actual value", y="sampled value")
75 _save_fig("example1-actual_value_vs_sampled_value")
76
77
78if __name__ == "__main__":
79 run_example()